인공지능에 대한 수요가 급증하면서 더 성능 좋은 칩 개발의 경쟁이 뜨겁습니다. 이번 포스팅에서는 IEEE Spectrum에 소개된 인공지능 학습 칩 개발에 대한 내용을 소개합니다.
개요
엔비디아, 오라클, 구글, 델을 포함한 13개의 기업이 현재 사용 중인 주요 신경망을 훈련시키는 데 걸리는 시간을 보고했습니다. 이 결과에는 엔비디아의 차세대 GPU인 B200과 구글의 향후 가속기인 트릴리움에 대한 첫 번째 정보도 포함되었습니다. B200은 오늘날 널리 사용되는 엔비디아 칩 H100에 비해 일부 테스트에서 두 배의 성능을 보였으며, 트릴리움은 구글이 2023년에 테스트한 칩보다 거의 4배의 성능 향상을 나타냈습니다.
이 벤치마크 테스트는 MLPerf v4.1이라 불리며, 추천 시스템, 대형 언어 모델(LLM) GPT-3와 BERT-large의 사전 훈련, Llama 2 70B 대형 언어 모델의 미세 조정, 객체 탐지, 그래프 노드 분류, 이미지 생성의 총 6가지 작업으로 구성되어 있습니다.
GPT-3 훈련은 방대한 작업이므로 벤치마크를 위해 전체 훈련을 수행하는 것은 비현실적입니다. 대신, 전문가들이 목표에 도달할 가능성이 높다고 판단한 지점까지 훈련을 진행하는 방식으로 테스트가 이루어집니다. Llama 2 70B의 경우, 처음부터 모델을 훈련시키는 것이 아니라 이미 훈련된 모델을 특정 전문성, 예를 들어 정부 문서에 맞춰 미세 조정하는 것이 목표입니다. 그래프 노드 분류는 사기 탐지와 신약 개발에 사용되는 기계 학습 유형입니다.
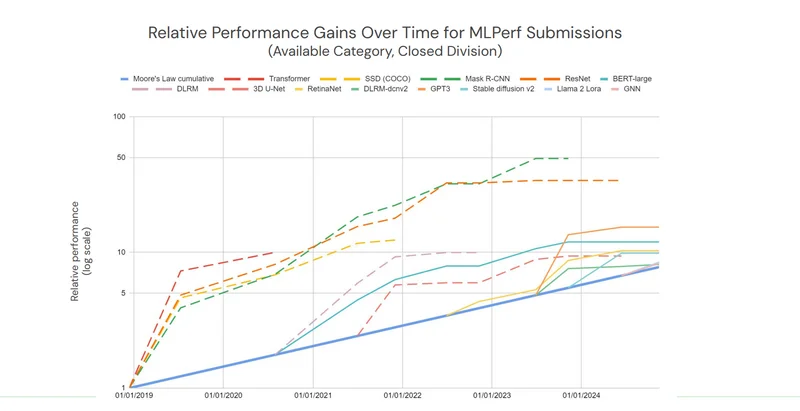
AI의 중요성이 주로 생성 AI로 진화함에 따라 테스트의 구성도 변화했습니다. MLPerf의 최신 버전은 벤치마크가 시작된 이후로 테스트 항목이 완전히 변경된 첫 번째 사례입니다. MLCommons의 벤치마크 작업을 이끄는 데이비드 캔터는 “이 시점에서 초기 벤치마크는 모두 단계적으로 폐지되었습니다”라고 언급했습니다. 이전 라운드에서는 일부 벤치마크를 수행하는 데 몇 초밖에 걸리지 않았습니다.
MLPerf의 계산에 따르면, 새 벤치마크 모음에서 AI 훈련의 향상 속도는 무어의 법칙에서 예상되는 속도의 약 두 배에 달합니다. 시간이 지남에 따라 결과가 초기 MLPerf의 등장 당시보다 더 빠르게 안정화되는 경향이 있습니다. 캔터는 이를 주로 기업들이 대형 시스템에서 벤치마크 테스트를 수행하는 방법을 터득했기 때문이라고 설명했습니다. 엔비디아와 구글 등은 시간이 지남에 따라 프로세서를 두 배로 늘리면 훈련 시간을 거의 절반으로 줄일 수 있는 소프트웨어와 네트워크 기술을 개발해 왔습니다.
엔비디아 블랙웰의 첫 훈련 결과
이번 라운드는 엔비디아의 차세대 GPU 아키텍처인 블랙웰의 첫 번째 훈련 테스트를 포함했습니다. GPT-3 훈련과 LLM 미세 조정에서 블랙웰(B200)은 GPU 한 대당 성능이 H100보다 약 두 배 향상되었습니다. 추천 시스템과 이미지 생성 작업에서는 성능 향상이 다소 줄어들었지만 여전히 상당하여 각각 64%와 62%의 성능 증가를 보였습니다.
엔비디아 B200 GPU에 구현된 블랙웰 아키텍처는 AI 속도를 높이기 위해 점점 더 낮은 정밀도의 숫자를 사용하는 추세를 지속하고 있습니다. ChatGPT, Llama2, Stable Diffusion과 같은 특정 트랜스포머 신경망 부분에서 엔비디아 H100 및 H200은 8비트 부동 소수점 숫자를 사용하지만, B200은 이를 4비트로 낮췄습니다.
구글, 6세대 하드웨어 공개
구글은 지난달에 공개한 6세대 TPU인 트릴리움의 첫 번째 결과와 5세대 TPU의 변형 모델인 Cloud TPU v5p의 두 번째 결과를 발표했습니다. 2023년 에디션에서는 구글이 효율성에 중점을 둔 5세대 TPU의 다른 변형 모델인 v5e를 공개했으나, 트릴리움은 이에 비해 GPT-3 훈련 작업에서 최대 3.8배의 성능 향상을 제공합니다.
그러나 모든 기업의 주요 경쟁자인 엔비디아와의 비교에서는 성과가 다소 미흡했습니다. 6,144개의 TPU v5p로 구성된 시스템은 GPT-3 훈련 목표에 도달하는 데 11.77분이 걸렸으며, 11,616개의 엔비디아 H100으로 구성된 시스템이 약 3.44분에 작업을 완료한 것에 비해 현저히 뒤처졌습니다. 최상위 TPU 시스템은 절반 크기의 H100 시스템보다 약 25초 빨랐을 뿐입니다.
v5p와 트릴리움을 각각 2048개의 TPU로 구성해 가장 근접하게 비교한 결과, 트릴리움은 GPT-3 훈련 시간을 약 2분 단축하여 v5p의 29.6분에서 거의 8%의 개선을 이루었습니다. 또 다른 차이점은 트릴리움이 v5p의 인텔 제온 대신 AMD Epyc CPU와 함께 사용된 점입니다.
구글은 Cloud TPU v5p를 사용하여 이미지 생성 모델인 Stable Diffusion을 훈련했습니다. Stable Diffusion은 26억 개의 파라미터로 구성되어 있어, MLPerf 참가자들은 GPT-3와 달리 체크포인트까지가 아닌 완전한 수렴까지 훈련하도록 요구받습니다. 1024개의 TPU로 구성된 시스템은 2분 26초 만에 작업을 완료하여 두 번째로 빠른 기록을 세웠으며, 동일한 규모의 엔비디아 H100 시스템보다 약 1분 뒤처졌습니다.
훈련 전력의 불투명성
신경망 훈련에 드는 높은 에너지 비용은 오랫동안 우려의 원인이었습니다. MLPerf는 이제 이를 측정하기 시작했으며, 에너지 부문에 참가한 유일한 기업은 델 테크놀로지스였습니다. 델은 64개의 엔비디아 H100 GPU와 16개의 인텔 제온 플래티넘 CPU가 장착된 8대의 서버 시스템으로 참여했습니다. 측정은 LLM 미세 조정 작업(Llama2 70B)에서만 이루어졌으며, 시스템은 5분 동안 16.4메가줄의 에너지를 소비해 평균 전력 5.4킬로와트를 기록했습니다. 이는 미국 평균 전기 요금을 기준으로 약 75센트의 비용에 해당합니다.
이 수치는 그 자체로는 큰 정보를 제공하지 않지만, 유사한 시스템의 전력 소비량에 대한 대략적인 기준을 제공할 수 있습니다. 예를 들어, 오라클은 동일한 수와 종류의 CPU 및 GPU를 사용하여 4분 45초의 유사한 성능 결과를 보고했습니다.
마무리
이번 포스팅에서는 MLPerf의 최신 벤치마크 테스트 결과와 엔비디아, 구글, 델을 포함한 주요 기업들이 AI 훈련 성능과 에너지 소비 측면에서 어떤 발전을 이루었는지 살펴보았습니다. 엔비디아의 차세대 GPU 아키텍처인 블랙웰과 구글의 6세대 TPU인 트릴리움의 성능은 AI 모델 훈련의 속도와 효율성을 높이며 주목할 만한 결과를 보여주었습니다. 하지만 고성능 AI 훈련이 막대한 전력을 소비한다는 점도 이번 벤치마크를 통해 확인할 수 있었으며, 앞으로 에너지 효율 개선이 더욱 중요해질 것으로 보입니다. AI 훈련에 대한 기술적 발전뿐만 아니라, 효율적인 에너지 사용 방안에 대한 관심이 높아지는 현재, MLPerf의 이러한 새로운 측정 시도는 관련 업계에 중요한 참고 자료가 될 것입니다.